About /robots.txt
In a nutshell
Web site owners use the /robots.txt file to give instructions about their site to web robots; this is called The Robots Exclusion Protocol.
It works likes this: a robot wants to vists a Web site URL, say http://www.example.com/welcome.html. Before it does so, it firsts checks for http://www.example.com/robots.txt, and finds:
User-agent: *
Disallow: /
The "User-agent: *" means this section applies to all robots. The "Disallow: /" tells the robot that it should not visit any pages on the site.
There are two important considerations when using /robots.txt:
- robots can ignore your /robots.txt. Especially malware robots that scan the web for security vulnerabilities, and email address harvesters used by spammers will pay no attention.
- the /robots.txt file is a publicly available file. Anyone can see what sections of your server you don't want robots to use.
Adding the
.global.prod.fastly.net extension to your domain (for example, www.example.com.global.prod.fastly.net) via the browser or in a cURL command can be used to test how your production site will perform using Fastly's services.
To prevent Google from accidentally crawling this test URL, we provide an internal robots.txt file that instructs Google's webcrawlers to ignore all pages for all hostnames that end in
.prod.fastly.net.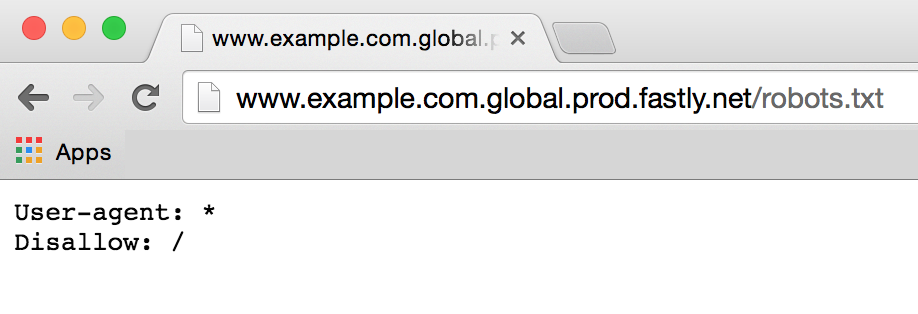
This internal robots.txt file cannot be customized via the Fastly web interface until after you have set the CNAME DNS record for your domain to point to
global.prod.fastly.net.

1 coment�rios:
Great post!!Thanks for sharing it with us....really needed.Our mission is to understand the value proposition of your business to better target your potential customers, in order to maximize the possibility of converting them into a qualified prospects.
marketing web
Post a Comment